Workflow of the application

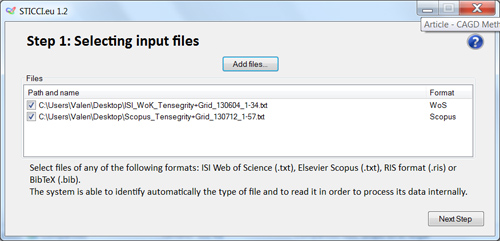
Step 1: Selecting input file
When launching the program, in Step 1, it just requires the user to select the files to work with. The system is able to read, in this version, some different types of text files, exported either from WoS, Scopus, BibTeX, RIS format or CSV. When loading it, the program automatically identifies which of those is the original format of the file.
If the software finds some repeated records that are duplicated as they come from different sources, it will ask the user if it is desirable to merge them into a unique record. It also gives the option of deciding the contents and the format of the record to be kept in the internal database.
Step 2: Searching similarities
When accepting the loaded file, the user will find in Step 2 another simple interface that will permit several operations to be selected that the user could accomplish, in a simple and intuitive manner. The different options and performances made by the software (explained above) could be selected or not depending on the preferences of the user: Search similarities by Citing author, Cited author, Full citation, Journal title or Toponymical variants.
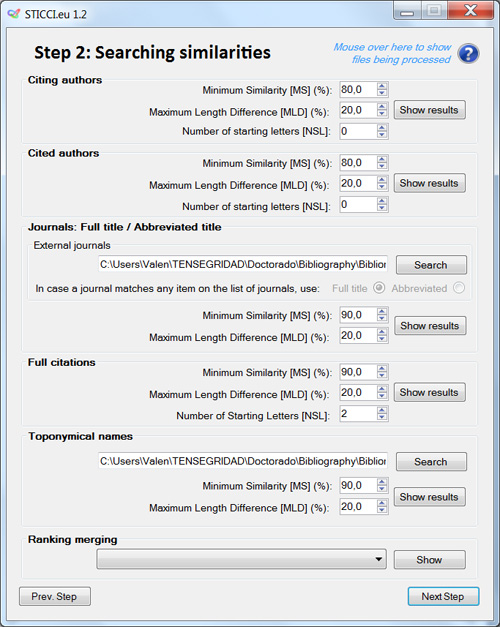
STICCI.eu lets the user to select three parameters in order to customize that search:
- MS = Minimum similarity (%): it defines the percentage of characters of two strings that must be equal (in type and position) to trigger the similarity flag.
- MLD = Maximum length difference (%): it defines the percentage of difference in length of two strings to trigger the similarity flag.
- NSL = Number of starting letters of a field concurring in different entries: It limits the comparisons only between entries whose fields share their first N number of letters (2 by default). This option reduces drastically the runtime for large datasets. If more accuracy is needed, this limit can be set to a lower amount of letters or it can be even set to zero in order to disable it.
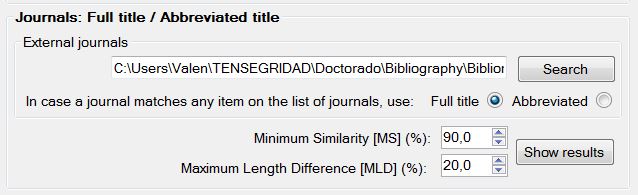
Abbreviated titles of Journals
STIICCI.eu gives the option of homogenizing the names of the sources if they are indexed journals of accessible databases. For instance, if in the field Source, a certain record has the name of the journal in an incorrect manner, it is possible to automatically substitute this entry by the accepted name in the JCR (Journal Citation Reports).
Variants of toponymical names
STICCI.eu also offers the possibility of homogenizing variants of toponymical names (referring to countries and relevant cities or regions). Most of these inconsistencies are due to the different languages in which they are written or to orthographical symbols like accents or dieresis.

Step 3: Selecting similarities to apply (Citing authors / Cited authors / Full citations)
Each one of those searches will lead to Step 3, where the user will be able to define which similarities must be combined and in which style. In the particular case of the search of similarities among full citations, the selection could be independent for each different field (author, title, source, volume or year). As explained above, in this window, visual tools, by means of colors, will help the user to locate the most feasible similarities (in blue), and the more ambiguous (in red), depending on the partial and total counters of each coincidence.
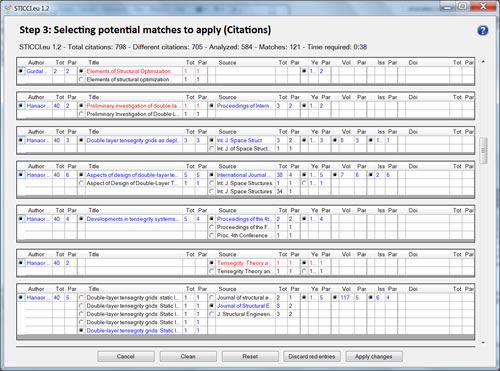
Ranking Merging
After applying all the changes done automatically by the system and refined by the user, the interface of Step 2 is displayed again, where it is possible to do as many additional searches and combinations as desired. A powerful tool is the so-called “Ranking Merging”, where the user can see the ranking of the most common attributes (cited authors, journals, full citations, etc.) and merge those who can easily be detected as being the same one.
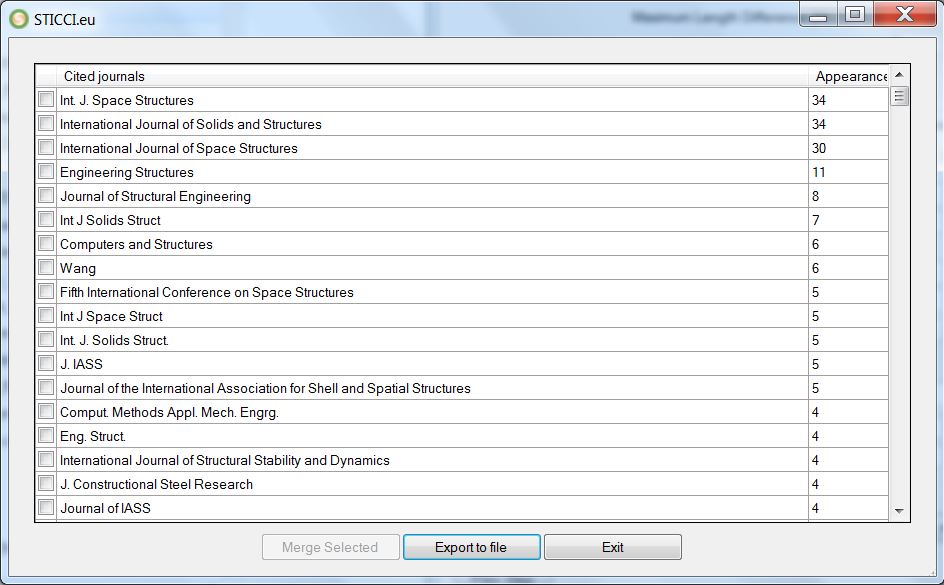
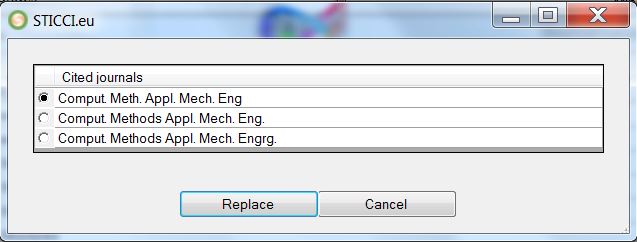
After the selection of several items to be merged, the following window will be shown:
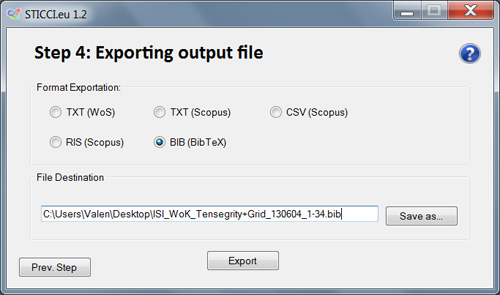
Step 4: Exporting output file
Once the selection is done and the user approves all the purging and merging done during the previous process, in the final window, Step 4, it is possible to decide the output format of the clean and homogenized dataset: WoS, Scopus, BibTeX, RIS format or CSV. Finally, in addition to the output file, already clean, purged and corrected, the program generates also a log file with an excerpt of the corrections made, the merged entries and the de-duplicated records.